트랜스포머와 같은 신경망에서 이것이 어떻게 작동하는지 구체적으로 알아보겠습니다.
Encode position information
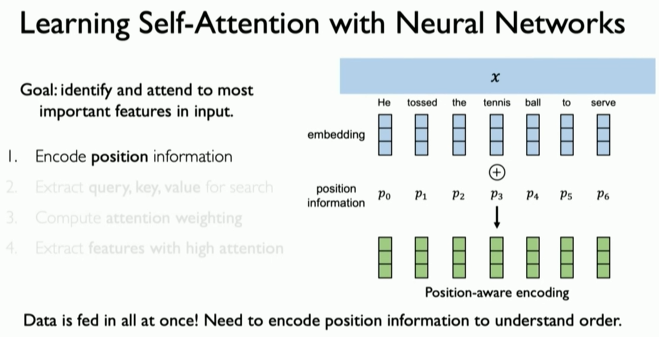
언어 예제로 돌아가 보자면, 우리의 목표는 이 입력 문장에서 의미론적으로 중요한 특징들을 식별하고 주목하는 것이다.
첫 번째 단계는 시퀀스를 갖는 것이다.
우리는 순서를 갖고 있다. 반복을 제거했으며, 모든 시간 단계를 한 번에 입력하고 있다. 여전히 순서와 위치 의존성에 대한 정보를 인코딩하고 캡처할 방법이 필요하다.
이것이 수행되는 방식은 위치 인코딩(positional encoding)이라는 아이디어를 통해 순서 정보를 포함시키는 것이다. 이는 시퀀스에 내재된 순서 정보를 캡처한다. 간단히 설명하자면, 이 아이디어는 이전에 소개한 *임베딩(embedding)과 관련이 있다. 신경망 레이어를 사용하여 텍스트 내에서 순서에 따른 상대적 관계를 캡처하는 위치 정보를 인코딩한다. 그리고 시간 단계에 모두 한 번에 처리할 수 있으며, 더 이상 시간 단계의 개념이 없다. 데이터는 단일하지만, 여전히 위치 순서 정보를 캡처하는 인코딩을 학습했다.
*임베딩이란? 임베딩은 말 그대로 "무언가를 안에 넣는 것" 여기서는 글자나 단어 숫자 등을 공간 속에 넣는다는 것을 의미한다. 예를 들어 "고양이"나 "강아지"를 컴퓨터가 이해할 수 있도록 숫자로 표현하는 것, 그렇게 숫자로 변화된 단어를 임베딩이라고 한다.
* 쉽게 설명 *
먼저, 문장에서 단어들의 순서를 알아야 한다. 위치 정보를 인코딩해서 각 단어의 순서를 기억한다. 이렇게 하면 컴퓨터는 단어의 순서를 고려하여 문장을 이해할 수 있다.
Extract query, key, value for search
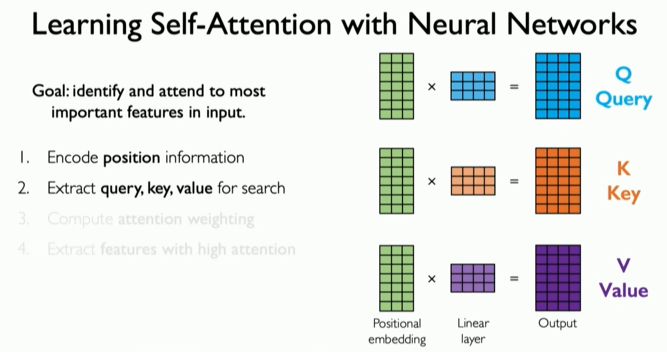
이제 우리의 다음 단계는 이 인코딩을 사용하여 무엇에 주의를 기울일지 파악하는 것이다. 유튜브 예제로 소개한 검색 작업과 정확히 같다. 즉, 쿼리를 추출하고, 키를 추출하고, 값을 추출하여 서로 연관시키는 것이다.
주어진 위치 인코딩을 통해 주의(attention)가 하는 일은 신경망 레이어를 적용하여 그것을 변환하는 것이다. 먼저 쿼리를 생성한다. 이를 위해 별도의 신경망 레이어를 사용한다. 이는 다른 가중치와 다른 파라미터 세트를 사용하여 위치 임베딩을 다른 방식으로 변환하여 두 번째 출력인 키를 생성한다. 마지막으로 이 작업은 세 번째 레이어와 세 번째 가중치 세트로 반복되어 값을 생성한다.
이제 쿼리, 키, 값을 손에 넣었으므로, 이들을 서로 비교하여 네트워크가 자기 입력에서 어디에 주의를 기울여야 할지, 무엇이 중요한지를 파악할 수 있다. 이것이 핵심 아이디어다.
*쉽게 설명*
이제 문장의 각 단어에서 쿼리(Query), 키(Key), 값(Value)이라는 세 가지 정보를 추출한다.
- 쿼리(Query): 내가 찾고 싶은 정보.
- 키(Key): 내가 찾고 싶은 정보가 어디에 있는지 알려주는 열쇠.
- 값(Value): 실제로 찾고 싶은 정보 자체.
예를 들어, "학교"라는 단어를 생각해보자. 쿼리는 "학교에 대한 정보가 어디에 있지?"라고 물어보는 거고, 키는 "학교"라는 단어가 문장에 있는지 확인하는 역할을 한다. 값은 "학교"에 대한 실제 정보를 가져온다.
Compute attention weighting

네트워크가 자기 입력에서 무엇에 주의를 기울여야 하는지 파악하는 것이 중요하며, 이것이 유사성 메트릭 또는 어텐션 점수(Attention Score)의 핵심 아이디어다.
우리가 하는 일은 쿼리와 키 사이의 유사성 점수를 계산하는 것이다. 이 쿼리와 키 값들은 단순히 숫자의 배열이며, 이를 공간에서의 벡터로 생각할 수 있다. 쿼리 벡터와 키 벡터는 각각 다른 벡터이다. 이 두 벡터가 얼마나 유사한지 이해하기 위해 우리는 내적(Dot Product)을 취하고 이를 스케일링하여 비교한다. 이는 이 벡터들이 얼마나 유사한지, 즉 같은 방향을 가리키고 있는지를 캡처한다. 이것이 유사성 메트릭이며, 약간의 선형 대수학에 익숙하다면 이것이 코사인 유사도(Cosine Similarity) 작업으로도 알려져 있다는 것을 알 수 있다.
이 작업은 행렬에도 동일하게 적용된다. 쿼리와 키 행렬에 내적 연산을 적용하면 이 유사성 메트릭이 도출된다. 이는 입력 내에서 네트워크가 실제로 주의를 기울여야 할 부분을 정의하는 다음 단계, 즉 어텐션 가중치(Attention Weight)를 계산하는 데 매우 중요하다.

이 작업은 입력 데이터의 구성 요소들이 서로 어떻게 관련되는지를 정의하는 점수를 제공한다.
예를 들어 문장이 주어졌을 때, 우리가 이 유사성 점수를 계산하면, 시퀀셜 데이터의 구성 요소들 간의 관계를 정의하는 가중치를 생각할 수 있다. 예를 들어 "그는 목표를 위해 서브하려고 테니스 공을 던졌다"라는 문장에서 시퀀스 내에서 서로 관련된 단어들은 높은 주의 가중치를 가져야 한다. 공(ball)은 테니스(tennis)와 관련이 있다. 이 메트릭 자체가 우리의 주의 가중치이다. 우리가 한 일은 그 유사성 점수를 소프트맥스(softmax) 함수에 통과시킨 것이다. 이 함수는 값들을 0과 1 사이로 제한한다. 따라서 이것들을 상대적인 주의 가중치의 점수로 생각할 수 있다.
마지막으로, 이제 우리는 이 유사성의 개념과 내부적인 자기 관계를 캡처할 수 있는 메트릭을 가지게 된다.
*쉽게 설명*
이제 쿼리(Query)와 키(Key)를 비교해서 각 단어가 얼마나 중요한지 계산한다. 중요한 단어일수록 높은 점수를 받게 된다. 예를 들어, "시험"이라는 단어가 "과학"이라는 단어와 얼마나 관련이 있는지 점수를 매긴다. 이렇게 해서 각 단어의 중요도를 나타내는 어텐션 가중치를 계산한다.
Extract features with high attention

이제 우리는 이 메트릭을 사용하여 높은 주목을 받을 만한 특징들을 추출할 수 있다. 이것이 바로 자기 주의 메커니즘의 마지막 단계이다. 우리는 그 주의 가중치 행렬을 값과 곱하여 초기 데이터를 변환한 출력을 얻는다. 이는 높은 주의를 받는 특징들을 반영한다.
*쉽게 설명*
마지막으로, 계산된 어텐션 가중치를 사용해서 중요한 단어들에 집중한다. 중요도가 높은 단어들의 특징을 추출해서 문장의 의미를 더 잘 이해하도록 도와준다. 예를 들어, "오늘 학교에서 과학 시험을 봤다"라는 문장에서 "과학"과 "시험"이 높은 어텐션 점수를 받았다면, 이 단어들에 집중해서 문장의 중요한 정보를 추출하는 것이다.
'Artificial Intelligence > Deep Leaning' 카테고리의 다른 글
| Attention Is All You Need (0) | 2024.06.18 |
|---|---|
| RNN Applications & Limitations(RNN 응용 사례 및 한계) (2) | 2024.06.17 |
| Backpropagation Through Time(BPTT): 역전파 알고리즘 (5) | 2024.03.25 |
| A Sequence Modeling Problem: Predict the Next Word (시퀀스 모델링 문제: 다음 단어 예측하기) (0) | 2024.03.08 |
| Recurrent Neural Networks(RNNs) (9) | 2024.02.29 |



