
이미지 설명
Underfitting: 데이터 포인트와 단순 선형 모델이 그려져 있다.
Overfitting: 데이터 포인트와 적절한 복잡성의 모델이 그려져 있다.
Ideal fit: 데이터 포인트와 적절한 복잡성의 모델이 그려져 있다.
신경망 확률적 경사 하강법으로 최적화할 때 우리는 과적합이라는 문제에 직면한다. 과적합은 모델이 훈련 데이터의 패턴을 너무 정확하게 학습하여 테스트 데이터에 일반화되지 못하는 현상이다.
Underfitting(과소적합)
- 간단한 선형 모델이 훈련 데이터에 잘 맞지 않는 것을 보여준다. 이는 데이터가 선형적이 아니기 때문이다.
Overfitting(과적합)
- 너무 복잡한 모델이 훈련 데이터의 모든 잡음까지 학습하여 테스트 데이터에 일반화되지 못하는 것을 보여준다.
Ideal fit(적절한 복장)
- 적절한 복잡성의 모델이 훈련 데이터의 일반적인 패턴을 학습하여 테스트 데이터에도 잘 일반화될 수 있음을 보여준다.
과적합의 문제를 해결하기 위한 방법
- 정규화: 모델의 복잡성을 제한하여 잡음에 민감하게 만든다.
- Dropout: 훈련 과정에서 일부 뉴런을 임시적으로 비활성화하여 모델의 일반화 능력을 향상시킨다.
- 조기 종료: 과적합을 방지하고 일반화 성능을 향상 키기는 효과적인 정규화 기법이다.
정규화
정규화는 무엇인가?:
정규화는 최적화 문제를 제한하여 복잡한 모델을 억제하는 기법이다. 즉, 신경망이 훈련 데이터에 너무 맞춰지지 않도록 규칙을 정하는 것이다.
정규화가 필요한 이유는:
정규화는 보지 않는 데이터에서도 모델의 일반화 성능을 향상시킨다. 다시 말해, 훈련 데이터에서만 잘 작동하는 게 아니라 새로운 데이터에서도 정확하게 예측할 수 있도록 돕는 기술이다.
어떻게 작동하는가?:
정규화는 모델의 복잡성을 측정한 값에 벌칙금을 부과한다. 즉, 너무 복잡한 모델은 훈련 과정에서 성능이 떨어지게 된다. 이를 통해 모델이 훈련 데이터의 모든 잡음까지 학습하지 않고 일반적인 패턴만을 학습하도록 유도한다.
Dropout
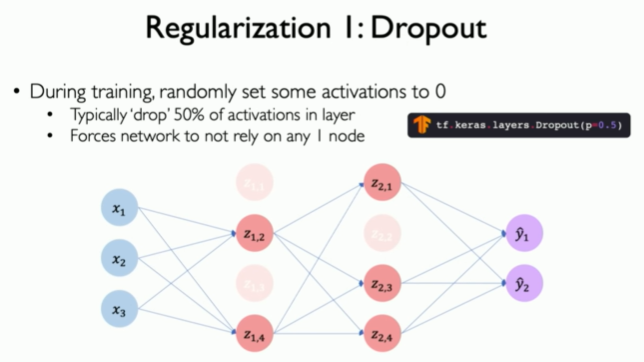
위의 이미지는 딥 뉴럴 네트워크를 나타낸다. 각 뉴런의 노드라고도 불리며 서로 연결되어 있다. 이미지에는 몇 개의 뉴런이 흐리게 표시되어 있다. 이는 드롭아웃이 발생하고 해당 뉴런이 비활성화되었음을 나타낸다.
가장 인기 있는 딥 러닝 정규화 기술은 드롭아웃이다. 드롭아웃은 훈련 과정에서 뉴런 일부를 무작위로 선택하여 비활성화하는 간단한 기법이다. 이를 통해 모델이 특정 뉴런에 너무 의존하지 않도록 하고 더 일반적인 패턴을 학습하도록 유도한다.
드롭아웃의 장점:
- 과적합 감소: 드롭아웃은 모델이 훈련 데이터에 너무 맞춰지는 것을 방지하여 테스트 데이터에 대한 일반화 성능을 향상시킨다.
- 앙상블 학습 효과: 드롭아웃은 훈련 과정마다 서로 다른 뉴런을 사용하여 앙상블 학습과 유사한 효과를 낸다.
- 훈련 속도 향상: 드롭아웃은 비활성화된 뉴런의 가중치를 업데이트하지 않아 훈연 속도를 향상시킬 수 있다.
조기 종료(Early Stopping)

위의 이미지에서 x축은 훈련 횟수(Epoch)를 나타낸다. y축은 손실(Loss)을 나타낸다.
초록색 선은 훈련 데이터에 대한 손실이고 파란색 선은 테스트 데이터에 대한 손실이다.
두 번째 정규화 기법은 조기 종료(Early Stopping)이다. 이는 신경망을 넘어서는 광범위한 정규화 기법이다.
과적합은 모델이 훈련 데이터를 테스트 데이터보다 더 잘 표현하기 시작할 때 발생한다. 이를 방지하기 위해 훈련 데이터의 일부를 따로 떼어두고 훈련하지 않고, 일종의 테스트 데이터 세트로 사용할 수 있다. 이를 통해 모델이 보이지 않는 부분의 데이터를 어떻게 학습하는지 모니터링할 수 있다.
훈련 과정에서 훈련 세트와 테스트 세트 모두에서 모델의 성능을 그래프로 그릴 수 있다. 네트워크가 훈련되면 처음에는 두 손실 모두 감소한다. 그러나 손실이 정체되기 시작하고 증가하는 지점이 있다. 훈련 손실이 실제로 증가하기 시작하는 지점은 테스트 손실이 실제로 증가하기 시작하는 지점과 정확히 일치한다. 이 지점에서부터 훈련 데이터에 대한 과적합이 시작되기 때문이다. 이 패턴은 기본적으로 나머지 훈련 동안 계속된다.
이 중간 지점은 훈련을 중단해야 하는 지점이다. 이 지점 이후에는 테스트 세트의 정확도가 더 나빠질 뿐이기 때문이다. 따라서 이 지점에서 모델을 조기 중단하고 성능을 정규화해야 한다. 이 지점 이전에 중단하는 것도 좋지 않다. 이 경우 테스트 데이터에서 더 나은 모델을 얻을 수 있었던 과소적합 모델이 생성된다. 조기 종료는 시기의 적절함 중요하다. 너무 늦게 중단할 수도 없고 너무 일찍 중단할 수도 없다.
조기 종료는 과적합을 방지하고 일반화 성능을 향상 시키기는 효과적인 정규화 기법이다. 훈련 과정에서 테스트 세트의 손실을 모니터링하고 손실이 증가하기 시작하는 지점에서 훈련을 중단하는 것이 핵심이다.

지금까지 했던 내용을 정리하자면
1. 뉴런과 퍼셉트론: 모든 신경망의 기본 구성 요소인 단일 뉴런과 퍼셉트론에 대해 살펴보았다.
2. 신경망 층과 딥 러닝: 단일 뉴런을 더 큰 신경망 층으로 연결하고, 이를 통해 딥 러닝 네트워크를 구성하는 방법을 배웠다.
3. 훈련, 역전파 및 최적화: 데이터 세트에 신경망을 적용하는 방법, 역전파를 통한 학습 방법, 시스템을 최적화하기 위한 팁과 트릭에 대해 알아보았다.
다음 블로그에서는 딥 시퀀스 모델링에 관한 이야기를 할 예정이며, 특히 트랜스포머 아키텍처와 어텐션 메커니즘이라는 흥미로운 새로운 모델에 대해 다룰 것이다.
'Artificial Intelligence > Deep Leaning' 카테고리의 다른 글
| Neurons with Recurrence (7) | 2024.02.01 |
|---|---|
| Sequence Modeling(시퀸스 모델링) (5) | 2024.01.26 |
| Neural Network in Practice: Mini-batches (22) | 2024.01.13 |
| Neural Network in Practice: Optimization(실제 신경망: 최적화) (0) | 2024.01.11 |
| 역전파 알고리즘(Backpropagation algorithm) (6) | 2024.01.05 |



