앞서 배운 x가 1개인 선형 회귀를 단순 선형 회귀라고 한다. 이번 챕터에서는 다수의 x로부터 y를 예측하는 다중 선형 회귀에 대해서 이해한다.
1. 데이터에 대한 이해(Data Definition)
다음과 같은 훈연 데이터가 있습니다. 앞서 배운 단순 선형 회귀와 다른 점은 독립 변수 x의 개수가 이제 1개가 아닌 3개라는 점입니다. 3개의 퀴즈 점수로부터 최종 점수를 예측하는 모델을 만들어보자
독립 변수 x의 개수가 3개이므로 이를 수식으로 표현하면 아래와 같다.
H(x) = w1x2 + w2x2 + w3x3 + b
2. 파이토치로 구현하기
우선 필요한 도구들을 임포트 하고 랜덤 시드를 고정한다.
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optimtorch.manual_seed(1)
이제 훈련 데이터를 선언해 보자.
H(x) = w1x2 + w2x2 + w3x3 + b
위의 식을 보면 이번에는 단순 선형 회귀와 다르게 x의 개수가 3개이다. 그러니 x를 3개 선언한다.
# 훈련 데이터
x1_train = torch.FloatTensor([[73], [93], [89], [96], [73]])
x2_train = torch.FloatTensor([[80], [88], [91], [98], [66]])
x3_train = torch.FloatTensor([[75], [93], [90], [100], [70]])
y_train = torch.FloatTensor([[152], [185], [180], [196], [142]])
이제 가중치 피라미터를 w로 하고, 편향 피라미터를 b로 선언한다. 가중치 w도 3개 선언해주어야 한다.
# 가중치 w와 편향 b 초기화
w1 = torch.zeros(1, requires_grad=True)
w2 = torch.zeros(1, requires_grad=True)
w3 = torch.zeros(1, requires_grad=True)
b = torch.zeros(1, requires_grad=True)이제 가설, 비용 함수, 옵티마이저를 선언한 후에 경사 하강법을 1,000회 반복합니다.
# 경사하강법 옵티마이저(optimizer)를 생성한다.
optimizer = optim.SGD([w1, w2, w3, b], lr=1e-5)
#[w1, w2, w3, b]: 옵티마이저가 조정할 가중치와 편향 파라미터를 지정
#lr=1e-5 학습률을 설정하여, 각 업데이트 단계에서 파라미터가 얼마나 크게 조정될지 결정하는 값이다.
nb_epochs = 1000 #훈련을 1000번 반복한다.
for epoch in range(nb_epochs + 1): #훈련루프 시작
# H(x) 계산/ 모델의 예측값을 계산한다.
hypothesis = x1_train * w1 + x2_train * w2 + x3_train * w3 + b
# cost 계산/ 평균 제곱 오차를 계산하여 예측값과 실제값의 차이를 측정한다.
cost = torch.mean((hypothesis - y_train) ** 2)
# cost로 H(x) 개선
optimizer.zero_grad() #이전 업데이트에서 계산된 기울기를 0으로 초기화한다.
cost.backward() #비용 함수에 대한 기울기를 계산한다.
optimizer.step() #계산된 기울기를 사용하여 피라미터를 업데이트한다.
# 100번마다 로그 출력
if epoch % 100 == 0:
print('Epoch {:4d}/{} w1: {:.3f} w2: {:.3f} w3: {:.3f} b: {:.3f} Cost: {:.6f}'.format(
epoch, nb_epochs, w1.item(), w2.item(), w3.item(), b.item(), cost.item()
))Epoch 0/1000 w1: 0.294 w2: 0.294 w3: 0.297 b: 0.003 Cost: 29661.800781
Epoch 100/1000 w1: 0.674 w2: 0.661 w3: 0.676 b: 0.008 Cost: 1.563634
Epoch 200/1000 w1: 0.679 w2: 0.655 w3: 0.677 b: 0.008 Cost: 1.497607
Epoch 300/1000 w1: 0.684 w2: 0.649 w3: 0.677 b: 0.008 Cost: 1.435026
Epoch 400/1000 w1: 0.689 w2: 0.643 w3: 0.678 b: 0.008 Cost: 1.375730
Epoch 500/1000 w1: 0.694 w2: 0.638 w3: 0.678 b: 0.009 Cost: 1.319511
Epoch 600/1000 w1: 0.699 w2: 0.633 w3: 0.679 b: 0.009 Cost: 1.266222
Epoch 700/1000 w1: 0.704 w2: 0.627 w3: 0.679 b: 0.009 Cost: 1.215696
Epoch 800/1000 w1: 0.709 w2: 0.622 w3: 0.679 b: 0.009 Cost: 1.167818
Epoch 900/1000 w1: 0.713 w2: 0.617 w3: 0.680 b: 0.009 Cost: 1.122429
Epoch 1000/1000 w1: 0.718 w2: 0.613 w3: 0.680 b: 0.009 Cost: 1.079378위의 경우 가설을 선언하는 부분인 hypothesis = x1_train * w1 + x2_train * w2 + x3_train * w3 + b에서도 x_train의 개수만큼 w와 곱해주도록 작성해 준 것을 확인할 수 있다.
3. 벡터와 행렬 연산으로 바꾸기
위의 코드를 개선할 수 있는 부분이 있다. 이번에는 x의 개수가 3개였으니까 x1_train, x2_train, x3_train와 w1, w2, w3를 일일이 선언해 주었다. 그런데 x의 개수가 1,000개라고 가정해 보자. 위와 같은 방식을 고수할 경우 x_train ~ x_train1000을 전부 선언하고, w1 ~ w1000을 전부 선언해야 한다. 다시 말해 x와 w변수 선언만 총 합 2,000개를 해야 한다. 또한 가설을 선언하는 부분에서도 마찬가지로 x_train과 w의 곱셈이 이루어지는 항을 1,000개를 작성해야 한다. 이는 굉장히 비효율적이다.
이를 해결하기 위해 행렬 곱셈 연산(또는 벡터의 내적)을 사용한다.
- 행렬의 곱셈 과정에서 이루어지는 벡터 연산을 벡터의 내적(Dot Product)이라고 한다.

위의 그림은 행렬 곱셈 연산 과정에서 내적으로 1x7 + 2x9 + 3x11 = 58이 되는 과정을 보인다.
이 행렬 연산이 어떻게 현재 배우고 있는 가설과 상관이 있다는 걸까요?
바로 가설을 벡터와 행렬 연산으로 표현할 수 있기 때문입니다.
3-1. 벡터 연산으로 이해하기
H(x) = w1x2 + w2x2 + w3x3
위 식은 아래와 같이 두 벡터의 내적으로 표현할 수 있다.

두 벡터를 각각 x와 w로 표현한다면, 가설은 다음과 같다.
H(X) = XW
x의 개수가 3개였음에도 이제는 x와 w라는 두 개의 변수로 표현된 것을 볼 수 있다.
3-2. 행렬 연산으로 이해하기
훈련 데이터를 살펴보고, 벡터와 행렬 연산을 통해 가설 H(X)를 표현해 보자.
전체 훈련 데이터의 개수를 셀 수 있는 1개의 단위를 샘플(sample)이라고 한다. 현재 샘플의 수는 총 5개이다. 각 샘플에서 y를 결정하게 하는 각각의 독립 변수 x를 특성(feature)이라고 한다. 현재 특성은 3개다.
이는 독립 변수 x들의 수가(샘플의 수 x 특성의 수) = 15개임을 의미한다. 독립 변수 x들을(샘플의 수 X 특성의 수)의 크기를 가지는 하나의 행렬로 표현해 보자. 그리고 이 행렬을 X라고 하고
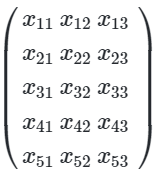
여기에 가중치 w1, w2, w3을 원소로 하는 벡터를 w라 하고 이를 곱해보자.

위의 식은 결과적으로 다음과 같다.
H(X) = XW
이 가설에 각 샘플에 더해지는 편향 b를 추가해 보자, 샘플 수만큼의 차원을 가지는 편향 벡터 B를 만들어 더한다.

위의 식은 결과적으로 다음과 같다.
H(X) = XW + B
결과적으로 전체 훈련 데이터의 가설 연산을 3개의 변수만으로 표현하자.
이와 같이 벡터와 행렬 연산은 식을 간단하게 해 줄 뿐만 아니라 다수의 샘플의 병렬 연산이므로 속도의 이점을 가진다.
4. 행렬 연산을 고려하여 파이토치로 구현하기
이번에는 행렬 연산을 고려하여 파이토치로 재구현해 보자.
이번에는 훈련 데이터 또한 행렬로 선언해야 한다.
x_train = torch.FloatTensor([[73, 80, 75],
[93, 88, 93],
[89, 91, 80],
[96, 98, 100],
[73, 66, 70]])
y_train = torch.FloatTensor([[152], [185], [180], [196], [142]])이전에 x_train을 3개나 구현했던 것과 다르게 이번에는 x_train 하나에 모든 샘플을 전부 선언하였다. 다시 말해(5x3) 행렬 X을 선언한 것이다.
x_train과 y_train의 크기(shape)를 출력해 보자.
print(x_train.shape)
print(y_train.shape)torch.Size([5, 3])
torch.Size([5, 1])각각(5 x 3) 행렬과 (5x1) 행렬(또는 벡터)의 크기를 가진다.
이제 가중치 W와 편향 b를 선언한다.
# 가중치와 편향 선언
W = torch.zeros((3, 1), requires_grad=True)
b = torch.zeros(1, requires_grad=True)여기서 주목할 점은 가중치 w의 크기가(3 x 1) 벡터라는 점이다. 행렬의 곱셈이 성립되려면 곱셈의 좌측에 있는 행렬의 열의 크기와 우측에 있는 행렬의 행의 크기가 일치해야 한다. 현재 X_train의 행렬의 크기는 (5 X 3)이며, W벡터의 크기는 (3 X 1)이므로 두 행렬과 벡터의 행렬곱이 가능하다. 행렬곱으로 가설을 선언하면 아래와 같다.
hypothesis = x_train.matmul(W) + b가설을 행렬곱으로 간단히 정의하였다. 이는 앞서 x_train과 w의 곱셈이 이루어지는 각 항을 전부 기재하여 가설을 선언했던 것과 대비된다. 이경우, 사용자가 독립 변수 x의 수를 후에 추가적으로 늘리고나 줄이더라도 위의 가설 선언 코드를 수정할 필요가 없다. 이제 해야 할 일은 비용 함수와 옵티마이저를 정의하고, 정해진 에포크만큼 훈련을 진행하는 일이다. 이를 반영한 전체 코드는 다음과 같다.
#훈련 데이터를 텐서로 준비
#5개의 샘플과 3개의 특성을 갖는 2차원 텐서
x_train = torch.FloatTensor([[73, 80, 75],
[93, 88, 93],
[89, 91, 80],
[96, 98, 100],
[73, 66, 70]])
#각 샘플에 대한 실제 성적을 담는 1차원 텐서이다.
y_train = torch.FloatTensor([[152], [185], [180], [196], [142]])
#가중치(w)와 편향(b)피라미터를 0으로 초기화한다.
#requires_grad=True로 설정하여 파라미터가 학습될 수 있도록 한다.
W = torch.zeros((3, 1), requires_grad=True)
b = torch.zeros(1, requires_grad=True)
#경사하강법 옵티마이저를 설정한다./ 학습률을 1e-5
optimizer = optim.SGD([W, b], lr=1e-5)
#훈련 루프
nb_epochs = 20 #훈련을 20번 반복한다.
for epoch in range(nb_epochs + 1): #가설을 계산한다. 행렬 곱셈을 통해 입력 데이터와 가중치를 곱하고 편향을 더한다.
# H(x) 계산
# 편향 b는 브로드 캐스팅되어 각 샘플에 더해집니다.
hypothesis = x_train.matmul(W) + b
# 평균 제곱 오차를 계산하여 오차를 측정한다.
cost = torch.mean((hypothesis - y_train) ** 2)
# cost로 H(x) 개선
optimizer.zero_grad() #기울기를 초기화
cost.backward() #비용 함수에 대한 기울기를 계산
optimizer.step() #계산된 기울기를 사용하여 피라미터를 업데이트 한다.
print('Epoch {:4d}/{} hypothesis: {} Cost: {:.6f}'.format(
epoch, nb_epochs, hypothesis.squeeze().detach(), cost.item()
))Epoch 0/20 hypothesis: tensor([0., 0., 0., 0., 0.]) Cost: 29661.800781
Epoch 1/20 hypothesis: tensor([66.7178, 80.1701, 76.1025, 86.0194, 61.1565]) Cost: 9537.694336
Epoch 2/20 hypothesis: tensor([104.5421, 125.6208, 119.2478, 134.7861, 95.8280]) Cost: 3069.590820
Epoch 3/20 hypothesis: tensor([125.9858, 151.3882, 143.7087, 162.4333, 115.4844]) Cost: 990.670288
Epoch 4/20 hypothesis: tensor([138.1429, 165.9963, 157.5768, 178.1071, 126.6283]) Cost: 322.481964
Epoch 5/20 hypothesis: tensor([145.0350, 174.2780, 165.4395, 186.9928, 132.9461]) Cost: 107.717064
Epoch 6/20 hypothesis: tensor([148.9423, 178.9731, 169.8976, 192.0301, 136.5279]) Cost: 38.687401
Epoch 7/20 hypothesis: tensor([151.1574, 181.6347, 172.4254, 194.8856, 138.5585]) Cost: 16.499046
Epoch 8/20 hypothesis: tensor([152.4131, 183.1435, 173.8590, 196.5042, 139.7097]) Cost: 9.365656
Epoch 9/20 hypothesis: tensor([153.1250, 183.9988, 174.6723, 197.4216, 140.3625]) Cost: 7.071105
Epoch 10/20 hypothesis: tensor([153.5285, 184.4835, 175.1338, 197.9415, 140.7325]) Cost: 6.33186
.
.
.
.
참고자료: PyTorch로 시작하는 딥 러닝 입문
'Artificial Intelligence > Machine Learning' 카테고리의 다른 글
| nn.Module로 구현하는 선형 회귀 (0) | 2024.03.04 |
|---|---|
| 자동 미분(Autograd) (8) | 2024.01.26 |
| Linear Regression(선형 회귀) (10) | 2024.01.24 |
| 머신 러닝 워크 플로우 (2) | 2023.12.22 |


