Recurrent Neural Networks(RNNs)

위의 이미지는 RNN의 내부 구조를 보여준다. 입력(x_t), 이전 상태(h_(t-1)), 갱신된 상태(h_t), 출력(y_t) 간의 관계를 나타낸다. 화살표는 정보 흐름을 나타낸다.
순환 신경망(RNN)의 핵심 개념은 내부 상태(h)를 유지 관리하고 시퀸스를 처리하면서 각 시간 단계에서 업데이트한다. 이 업데이트는 재귀 관계를 통해 계산되며, 이 관계는 이전 시간 단계의 정보(h_(t-1))와 현재 입력(x_t)을 모두 고려한다. 이 함수(f_W)는 가중치(W) 집합에 의해 정의되며, RNN이 시계열 데이터를 처리하는 동안 시간 단계마다 동일한 가중치 집합을 사용한다.
텍스트와 이미지 모두 RNN이 내부 상태를 사용하여 시퀸스 데이터를 처리한다는 점을 보여준다. 이 내부 상태는 이전 시간 단계의 정보를 저장하고 현재 입력과 결합하여 다음 예측을 생성한다. 이미지의 녹색 상자는 이 내부 상태 업데이트를 수행하는 함수를 나타낸다. 이 함수는 이전 상태 (h_(t-1))와 현재 입력(x_t)을 모두 입력으로 받는다. 함수는 가중치(W) 집합을 사용하여 내부 상태를 업데이트한다. 이 가중치 집합은 RNN이 시퀀스를 처리하는 동안 모든 시간 단계에서 동일한 게 유지된다.
예를 들어, 문장을 번역하는 RNN을 생각해보자, RNN은 처음에는 빈 상태로 시작한다. 첫 번째 단어를 입력받으면 RNN은 이 단어와 내부 상태를 사용하여 다음 단어를 예측한다. 이 예측은 올바른지 여부를 확인하고 내부 상태를 업데이트한다. 이 프로세스는 다음 단어에 대해 반복된다. RNN은 이전 단어의 정보를 사용하여 다음 단어를 더 정확하게 예측할 수 있다.
RNN Intuition

파이썬 코드를 사용하여 RNN구현 방법을 설명해보자.
먼저 문장을 예시로 들고 다음 단어를 예측하는 작업을 수행한다. 문장의 각 단어를 순환하며 RNN모델에 입력한다. 이때 이전 숨겨진 상태도 함께 입력된다. RNN모델은 입력받은 단어와 숨겨진 상태를 바탕으로 다음 단어를 예측하고 숨겨진 상태를 업데이트한다. 마지막 단어에 대한 예측은 모든 단어가 입력된 후 RNN 모델의 출력값이다.
RNN State Update and Output

RNN은 숨겨진 상태를 업데이트하고 동시에 예측 출력을 생성한다. 숨겨진 상태 업데이트는 이전 숨겨진 상태와 현재 입력을 사용하여 계산된다. 예측 출력은 숨겨진 상태를 사용하여 계산된다.
입력 벡터는 이전 숨겨진 상태와 함께 가중치 행렬 곱셈을 통해 숨겨진 상태 업데이트에 사용된다. 숨겨진 상태 업데이트는 또 다른 가중치 행렬 곱셈을 통해 출력 벡터에 사용된다.
RNNs: Computational Graph Across Time

위의 이미지는 RNN의 계산 그래프로 가로축은 시간 단계를 나타내고 세로축은 네트워크의 각 계층을 나타낸다. 각 시간 단계에서 입력 벡터, 숨겨진 상태 벡터 및 출력 벡터가 표시되었다. 화살표는 연결 및 데이터 흐름을 나타낸다.
- 입력 벡터(X)를 현재 숨겨진 상태 벡터(초록상자)에 연결한다.
- 이전 숨겨진 상태 벡터를 현재 숨겨진 상태 벡터에 연결하는 것이다.
- 현재 숨겨진 상태 벡터(초록색 상자)를 출력 벡터(y)에 연결한다.
순환 신경망의 계산 그래프를 시간에 따라 펼쳐지는 방식으로 정의한다. 지금까지 RNN을 보여주는 주된 방법은 왼쪽 그림과 같은 루프 모양 다이어그램이다. RNN을 시각화하고 이해하는 또 다른 방법은 이 반복을 개별 시간 단계에 걸쳐 시간에 따라 펼치는 것이다. 즉, 첫 번째 시간 단계에서 네트워크를 가져와 시퀀스의 모든 시간 단계를 처리할 때까지 앞으로 시간 단계를 반복적으로 펼칠 수 있다. 이 다이어그램을 좀 더 공식화하기 위해 입력을 숨겨진 상태 업데이트에 연결하는 가중치 행렬, 시간에 따라 내부 상태를 업데이트하는 데 사용되는 가중치 행렬, 마지막으로 예측 출력을 생성하는 업데이트를 정의하는 가중치 행렬을 정의할 수 있다. 여기서 이 세 가지 가중치 행렬 모두 모든 시간 단계에 대해 동일한 가중치 행렬을 재사용하고 있다. 즉, 정보를 순차적으로 처리하는 단일 매개변수 집합 또는 가중치 행렬 집합이다. 이제 RNN을 학습하는 방법과 이 시간 처리 및 시간 의존성을 감안하여 손실 함수를 정의하는 방법에 대해 생각하기 시작할 수 있다.
각 시간 단계에서의 계산된 손실 값과 같고 이제 각 시간 단계별 예측을 실제 레이블과 비교하여 해당 타임스탬프에 대한 손실 값을 생성할 수 있다. 마지막으로 이러한 모든 개별 손실 항목을 합하여 RNN 입력에 대한 총손실을 얻을 수 있다.


위의 코드는 텐서플로우로 RNN구현 방법에 대한 예시이다. tf.keras.layers.SimpleRNN클래스를 사용하여 RNN 레이어를 정의한다. SimpleRNN클래스는 units 매개변수를 사용하여 RNN의 크기를 지정한다.
숨겨진 상태와 가중치 행렬의 포기화를 통해 정의할 수 있으며, 일반적으로 둘 다 0으로 초기화한다. 다음으로 x를 처리하기 위해 RNN네트워크를 통해 실제로 전달하는 방법을 정의할 수 있다. 이 전달 연산에서 계산은 앞서 살펴본 것과 정확히 같다. 먼저 이전에 도입한 방정식에 따라 숨겨진 상태를 업데이트하고 그 숨겨진 상태를 변형된 버전인 예측 출력을 생성한다. 마지막 시간 단계에서 다음 RNN 연산을 수행하는 데 필요한 갱신된 숨겨진 상태와 함께 출력을 반환한다.
RNNs for Sequence Modeling

이미지에 대해 설명드리자면 파란색 원(입력값) 보라색 원 (출력값)
Many to One: 하나의 문장(여러 단어)을 입력으로 받아 이미지에 대한 설명문(여러 단어)를 생성한다.
One to Many: 하나의 이미지를 입력으로 받아 이미지에 대한 설명문(여러 단어)를 생성한다.
Many to Many: 번역 작업처럼, 하나의 언어로 작성된 문장을 입력으로 받고 다른 언어로 구성된 문장을 출력으로 생성한다.
RNN은 다양한 종류의 시퀀스 모델링 문제에 적용할 수 있다.
Many to One: 여러 입력값으로 구성된 시퀀스를 하나의 출력값으로 예측한다.(예: 감정 분석)
One to Many: 정적인 하나의 입력값을 받아서 예측된 시퀸스를 생성한다.(예: 이미지 캡션 생성)
Many to Many: 입력 시퀸스를 받아서 각 시간 단계에서 예측값을 생성하는 시퀸스 대 시퀸스 작업이다.(예: 기계 번역)
정리
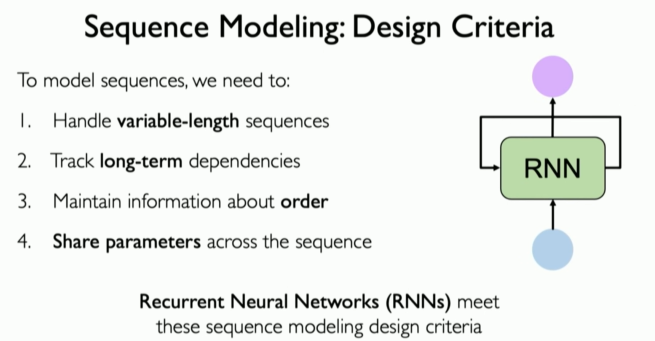
- 설계 기준과 RNN의 관계
1. 가변적인 시퀸스 길이(Variable Lengths):
RNN이 내부적으로 '숨겨진 상태'를 유지한다는 특성이 이 문제를 해결한다. 시퀀스의 길이에 관계없이 연산을 반복하므로 짧은 시퀀스건 긴 시퀸스건 처리할 수 있다.
2. 시간에 따른 의존성 학습(Long-Term Denpendencies):
이론적으로는 RNN의 숨겨진 상태 메커니즘을 통해 '과거 정보 기억'이 가능하다. 하지만 실제로는 RNN이 기울기 소실(vanishing gradients) 문제 등으로 인해 장기 의존성을 학습하는데 어려움을 겪을 수 있다.
3. 시퀀스 내의 순서(Order Matters):
RNN은 시퀀스 데이터를 순차적으로 처리한다. 이 과정에서 순서가 중요하다는 점을 반영할 수 있다.
4. 매개변수 공유(Parameter Sharing):
RNN은 동일한 가중치 집합(weight matrices)을 모든 시간 단계에 반복해서 적용한다. 이를 통해 계산 효율성이 높아지고 과적합(overfitting)의 위험이 줄어든다.
- RNN의 한계와 더 나은 아키텍처의 필요성
RNN은 시퀸스 모델링에 적합한 구조이지만, 특히 장기 의존성 학습에 약점을 드러낸다. 이는 다음과 같은 이유 때문이다.
1. 기울기 소실/ 폭발(Vanishing/Exploding Gradients): RNN을 학습시키는 기법(역전파)이 길이가 긴 시퀀스를 다루는 과정에서 문제를 일으킬 수 있다. 그래디언트 값이 지나치게 작아지거나 커지면 네트워크가 효과적으로 학습하지 못하게 된다.
2. 시간 순서에 지나치게 민감: RNN은 입력의 순서 변화에 민감하게 반응할 수 있어서 견고성이 떨어질 수 있다.
- 이러한 한계점을 극복하기 위해 더 발전된 아키텍처들이 제시되었다.
LSTM(Long Short-Term Memory): 기울기 문제를 완화하고 장기 의존성을 잘 학습할 수 있도록 설계되었다.
GRU(Gated Recurrent Unit): LSTM을 단순화한 구조를 효율성을 증대시킨다.
Transformer: Attention 메커니즘에 기반을 두어 매우 긴 시퀀스에서도 우수한 성능을 보이며, 병렬 계산을 통해 학습속도 또한 향상되었다.
'Artificial Intelligence > Deep Leaning' 카테고리의 다른 글
| Backpropagation Through Time(BPTT): 역전파 알고리즘 (4) | 2024.03.25 |
|---|---|
| A Sequence Modeling Problem: Predict the Next Word (시퀀스 모델링 문제: 다음 단어 예측하기) (0) | 2024.03.08 |
| Neurons with Recurrence (7) | 2024.02.01 |
| Sequence Modeling(시퀸스 모델링) (2) | 2024.01.26 |
| Neural Networks in Practice: Overfitting(과적합) (2) | 2024.01.19 |



